P0-visual — Register 3 (reafference) at the visual level
experiments/p0_visual.py
The visual analog of P0. Same body, same arena, same three-phase structure (calibration → self-test → exafference), same shape of result. The transducer changes from a single rangefinder whisker to a forward-facing camera, and the forward model changes from a heading-keyed binned predictor of range to an analytical predictor of the next frame from the current frame plus the agent's own yaw rate.
The claim survives the lift in input bandwidth, two orders of magnitude up.
What's deliberately minimal here — the SMN resolution principle
The eye is one undifferentiated camera rendering at 128 × 128, with one flat 8 × 8 = 64-token coarse-grid modulator. That is not a claim about perceptual resolution. In the SMN architecture, perceptual resolution is a function of CAZ density on the eye itself and the agent's internal capacities, not the raw transducer's pixel count. Since unmodulated input is dropped by default, raising the camera resolution alone would change nothing the architecture can use.
This minimal setup is therefore a deliberate floor: if the reafference register shows up at the simplest possible visual wiring, it survives the lift from whisker to vision. The successor experiments raise CAZ density on the eye itself (e.g. six CAZ pairs per eye modulating the visual field) and add known asymmetries between eyes as the experimental variable. This page is the baseline against which those successors will be read.
Setup
| component | this experiment |
|---|---|
| body | the P0 single-CAZ head (yaw hinge, pull-only antagonist pair m_left / m_right) |
| camera | one forward-facing camera mounted at the head's pivot so rotation is about its optical center — keeping the analytical predictor exact under the static-world assumption (smn_lab/model.py:build_p0v_xml) |
| transducer | EyeCamera → 128 × 128 grayscale frame at 50 Hz (smn_lab/vision.py) |
| forward model | AnalyticalFramePredictor — predicted next frame = current frame shifted horizontally by ω_z · Δt · focal_px, where focal_px = (W/2) / tan(fovx/2) |
| modulator | PatchResidualModulator — pools per-pixel |residual| into 8 × 8 = 64 patches; per-patch noise floor = p90 over calibration, clipped from below at 3.0 intensity units; fires when pooled residual exceeds the floor |
| world | the P0 arena, with a coloured wall on each side and a checker-textured floor for signal |
The body's head sweeps with θ_cmd = 0.55 · sin(2π · 0.45 · t) rad. The
camera's FOV is 90°; the head sweep amplitude (≈ 32°) is comfortably inside
that, so the world content stays visible across the sweep.
Conditions (three phases)
| window (s) | world | modulator | |
|---|---|---|---|
| Calibration | 0 – 12 | static (object hidden behind +x wall) | accumulates per-patch p90 residual |
| Self-test | 12 – 20 | static (object still hidden) | floor frozen; gating active |
| Exafference | 20 – 30 | object oscillates between x = 0.45 and x = 0.95 m at 0.5 Hz |
floor frozen; gating active |
| Post | 30 – 33 | object hidden again | floor frozen; gating active |
The agent's sweep is identical across phases — only what the world is doing differs.
Result
self-test mean |residual| = 6.22 fire-fraction = 0.061
exafference mean |residual| = 11.11 fire-fraction = 0.239 (×3.9 above self-test)
floor (median across patches) = 11.77
PASS: self-caused change cancels (almost no patch fires above its per-patch floor); world-caused change does not — the patches over the object's silhouette break through.
Result & interpretation
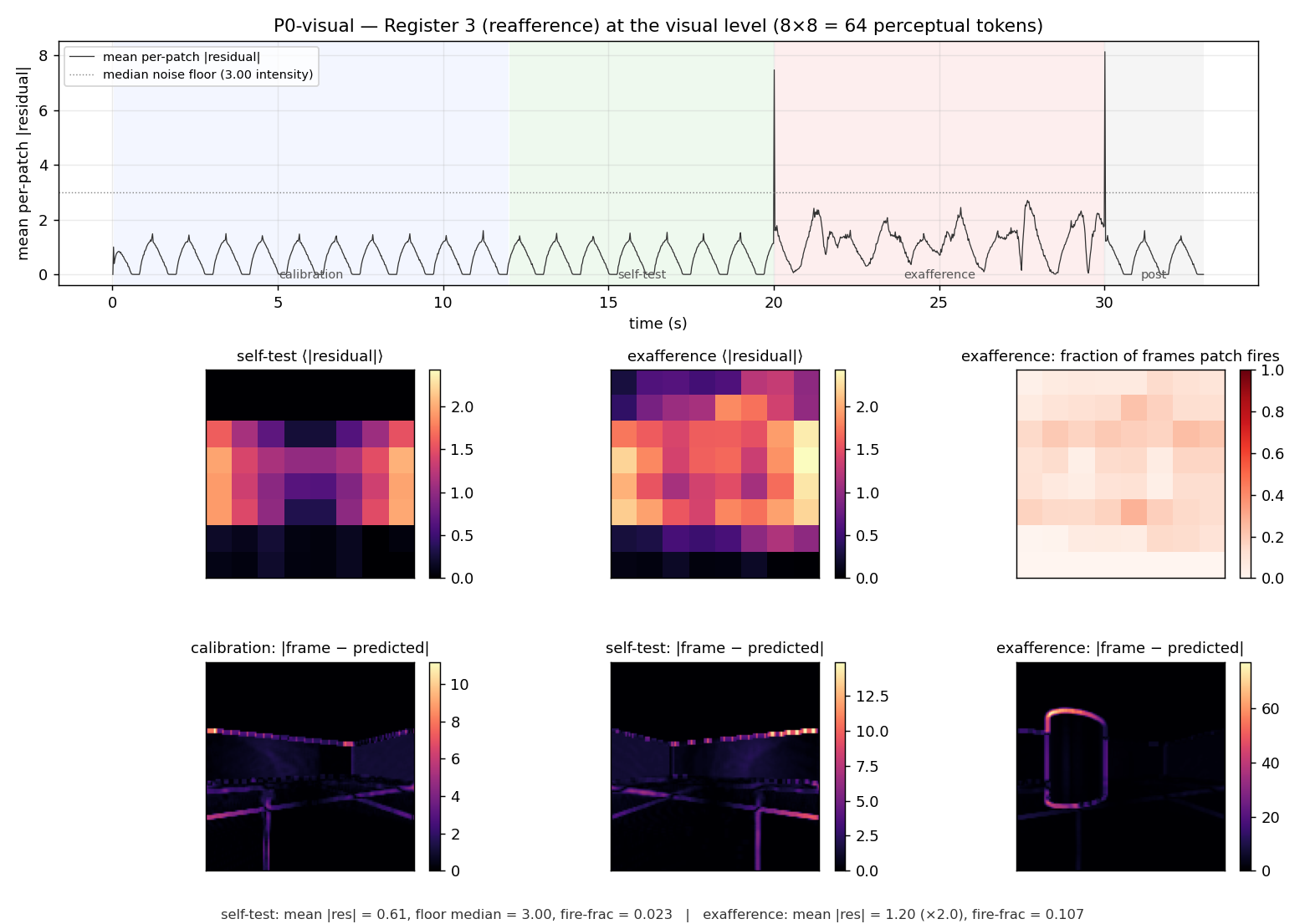
Top: mean per-patch |residual| over time, with the four phases shaded and
the median noise floor overlaid. Calibration and self-test sit at the floor;
exafference rises and oscillates in sync with the object's motion. Middle row:
per-phase residual heatmaps and the exafference fire-fraction map — a clear
central blob marks the patches the object occupies. Bottom row: representative
absolute-residual frames; the cylinder's silhouette is plainly visible in the
exafference panel as a bright vertical band.
The architecture's claim — the agent's own efference cancels its own sensory consequences; only world-caused change feeds the snapshot — survives the lift from one rangefinder reading to 64 patch tokens at the visual level. The contrast between self-test and exafference is not in the mean residual (most patches see no object at all and dilute the average) but in the fire-fraction at the modulator: how many patches break their per-patch floor.
What this experiment shows (and does not)
It does say:
- The reafference register is modality-independent at the SMN's level of description. The same closed-form claim — predicted from efference, subtracted, residual gates the snapshot — works at vision with no architectural rework, only a new transducer and a new forward model.
- The 8 × 8 coarse grid is sufficient to surface the object as a spatial pattern of fires. Pooling 16 × 16 pixel patches into single tokens already carries the object's silhouette into the snapshot — exactly what the M2 particular requires.
- The modulator's per-patch noise floor is what makes the visual snapshot quiet under self-motion: each patch develops its own tolerance, set by the warp predictor's worst-case error at that location. Wall-edge patches (where the linear-interpolation warp is least faithful) get a high floor; central patches get a low one. Both are right — they are the local cost of self-caused change, learned.
It does not say:
- Anything about what the snapshot tokens mean. They are residual
patches. Their accumulation into persistent objects (the construction of
particulars) is the next experiment (
p1_visual). - Anything about depth, parallax, or perception of distance. The static-world
assumption in the predictor is exact only for rotation about the camera's
optical center; we control this via the body geometry. Once the agent
translates, the predictor needs depth — that is
p2_visual. - Anything about resolution. The 128 × 128 frame is a bandwidth placeholder;
the architectural resolution claim has to be tested by varying the
modulator's CAZ density, not the camera's pixel count. That is the
p1_visual-and-after series.
What it adds to the assumptions
Common assumptions hold (planar rigid-body world; the single-CAZ head from P0). This experiment adds these specifics:
- The transducer is a forward-facing offscreen-rendered camera mounted at the head's pivot. Rotation about the optical center makes the analytical predictor exact under the static-world assumption.
- The world is textured: a colour-coded wall per side and a checker-textured floor, so the warp predictor has signal to work with. Untextured walls would still give a defensible (though noisier) result; the texture is for legibility of the residual frames, not for the claim itself.
- The modulator uses the p90 of calibration-window per-patch residuals clipped at 3.0 intensity units as the floor. The percentile is the only hyperparameter that affects the verdict materially; the chosen value lets ~6% of patches fire by chance under self-test (the kind of false-positive budget the snapshot can absorb) and ~24% under exafference.
- The 90° horizontal FOV is wide enough that the head's ≈ ±32° sweep keeps the object inside the view for the whole exafference window.
What is not added: depth (not needed under rotation-only motion); colour processing (we drop it at the transducer); a learned forward model (the analytical predictor is exact under the stated assumptions; a learned variant is a future experiment); multiple CAZs on the eye (the deliberate floor — see above).
Why this experiment is in the bench
It is the bench's first claim that the SMN architecture is modality- independent at its level of description. The reafference register predicted in the SMN paper, the one this bench reproduced from real physics at the haptic level in P0, survives the lift to vision with no architectural rework. The next visual experiments raise the CAZ density on the eye itself, add known asymmetries, and ask whether the architecture's predictions about resolution hold up the way its predictions about reafference just did.
A natural follow-up — flagged here, not built — is to feed the same RGB stream into two or three popular computer-vision pipelines (naive dense optical flow, classical background subtraction, a minimal visual-odometry front-end) under the same three-phase schedule, and compare what each puts through to "the world model". The architectural contrast — SMN's reafference is explicit in the agent's wiring; CV's pipelines reconstruct something similar but heuristically and post-hoc — would carry the point of the NetLogo integration page into a different research community.
Run it
cd experiments && ../.venv/bin/python p0_visual.py
Outputs: figures/p0_visual.png. Runtime: ~15 s on a laptop CPU.