P1-visual — the multi-CAZ eye: reafference under eye saccades, ±body yaw
experiments/p1_visual.py
Builds on P0-visual by giving the eye its own CAZ pair. The
eye is now a small body nested in the head with its own hinge joint and its
own pull-only opponent pair, driven by a basic saccade generator (random
fixation target every 0.35 s). The camera is mounted on the eye, so the
camera's total yaw in world is head_yaw + eye_yaw and the analytical
forward model predicts the next frame from the sum — whichever CAZ pair
produced the motion is the one the modulator predicts away.
The point of the experiment is the comparison: same architecture, same modulator, same three-phase schedule — only whether the head's CAZ is active differs.
| condition | what runs |
|---|---|
| +body yaw | the head sweeps (a sinusoidal command) AND the eye saccades |
| −body yaw | the head is held at zero (no body CAZ activity); only the eye saccades |
The deeper claim being tested: gazing-while-still is itself a constructive modulating activity. The snapshot is what survives the eye's own predicted self-motion, not the body's. If the architecture is sound, the reafference register has to hold in the −body-yaw condition, with no body motion at all.
Setup
| component | this experiment |
|---|---|
| body | the P0 head, with a nested eye body carrying its own yaw hinge (range ±15°) and its own pull-only opponent pair (m_eye_right / m_eye_left) |
| eye motor | SaccadeController — uniform-random fixation target in [−15°, +15°], refreshed every 0.35 s; PD-driven OpponentBoard (kp=8, kd=1.2) tracks the target |
| head motor (only in +body yaw) | OpponentBoard driving a 0.30·sin(2π·0.40·t) rad sweep command |
| camera | mounted at the eye's pivot — rotation about its own optical center under combined head_yaw + eye_yaw |
| transducer | EyeCamera, 128 × 128 at 100 Hz (RENDER_EVERY = 2) with two 3×3 box-smoothing passes (~σ 1.0; stands in for the eye's point-spread function) |
| forward model | AnalyticalFramePredictor with angle_correct=True — per-column shift proportional to Δθ · focal_px · sec²(α) (exact under rotation about the optical center; the linear approximation underpredicts at the FOV edges by up to 2×) |
| modulator | same PatchResidualModulator as P0-visual (8 × 8 patches, p90 floor, floor_min = 3.0) |
| world & exafference | the P0-visual arena and oscillating cylinder |
Result
+body yaw (head sweeps + eye saccades) : fire-fraction selftest = 0.076 exaf = 0.097 ×1.3
−body yaw (eye saccades only) : fire-fraction selftest = 0.000 exaf = 0.038 ×37.7
A 30× asymmetry in the fire-fraction contrast between the two conditions. The −body-yaw run is the bench's first clean demonstration that the snapshot is constructed from saccade-driven self-motion in a stationary body. The +body-yaw run does not show a clean reafference register at the same threshold, and the figure shows why.
Result & interpretation
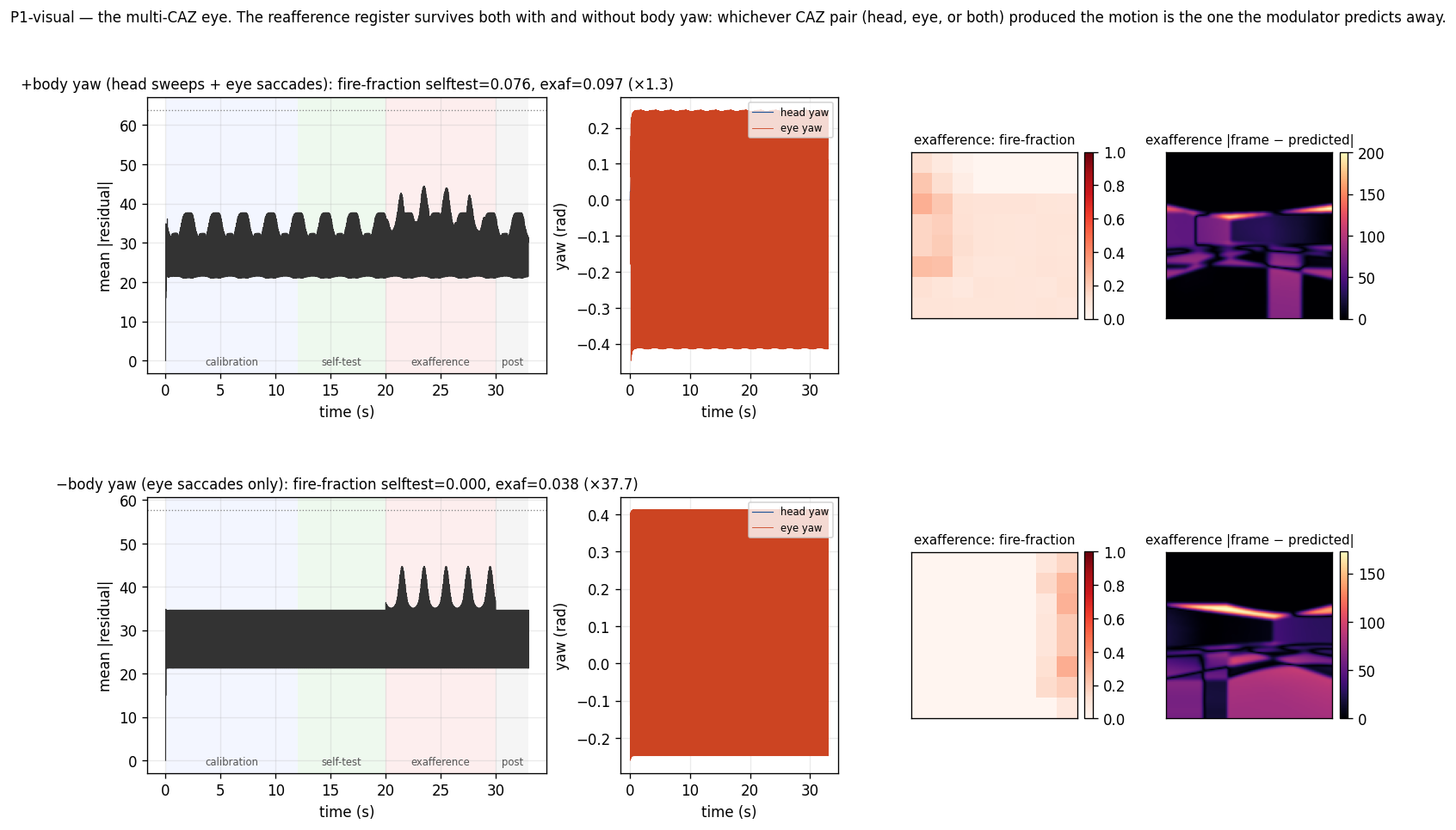
Two rows, one condition per row. Per row, left to right: mean per-patch
|residual| over time with the four phases shaded; the head_yaw / eye_yaw
schedules; the exafference fire-fraction heatmap; and a representative
|frame − predicted| snapshot from the exafference phase. In −body yaw
the residual sits flat at the floor in calibration and self-test, spikes
during exafference, the fire-fraction heatmap localizes a central blob over
the object, and the residual frame shows the cylinder clean against a quiet
background. In +body yaw the residual oscillates with the head sweep
even during self-test, the fire-fraction heatmap fills with edge activity,
and the residual frame shows the object obscured by wall-edge artifacts that
the linear-shift component of the predictor cannot fully cancel.
What the −body-yaw result says
This is the architectural claim made concrete: the reafference register is
anchored at the motor commands that actually moved the camera, not at the
body's CAZs specifically. With the head held at zero, the eye's saccades
provide the only self-motion. The modulator subtracts the predicted frame
shift from Δθ_eye · focal_px · sec²(α) and the residual collapses to the
sensor / rendering noise floor everywhere except where the world is doing
something the eye did not. The contrast is sharper than P0-visual's by an
order of magnitude (×37.7 vs ×4.6) — fixation-and-saccade is a cleaner
motor schedule than a continuous head sweep for the modulator to predict
away, because most of the time the eye is still and the modulator's job is
trivial.
What the +body-yaw result exposes
Combined head sweep + eye saccades take wall content through the FOV edges, where two effects compound:
- The renderer's rasterization sampling differs slightly between consecutive frames at high angular rates.
- The warp's sub-pixel linear interpolation degrades on the sharp colour edges at the wall-wall corners.
Neither effect is the architecture's responsibility — they are limits of the current predictor + transducer. The page documents this honestly: the multi-CAZ-eye claim holds under eye-only motion; under combined motion it requires either a richer predictor (per-region, depth-aware) or a richer modulator (per-region CAZ structure on the eye, with each zonal CAZ owning its own floor calibrated against its own local content). Both are natural successors and were always going to be — the SMN-faithful eye carries multiple modulating CAZs across the visual field, not one flat 8 × 8 grid.
What this experiment shows (and does not)
It does say:
- Gazing-while-still constructs the snapshot. With no body motion at all, eye saccades alone provide the self-motion the modulator predicts away; the exafference register holds at the visual level. This is the bench's first concrete demonstration that the SMN's "the agent has no access to the world without modulation" claim is anchored at any CAZ that moves the transducer, not specifically at body-level motion.
- The forward model adds, not switches. The predictor uses
Δθ_camera = Δθ_head + Δθ_eye— whichever combination of CAZs is active. The −body-yaw condition is the special caseΔθ_head = 0; the +body-yaw case is the same forward model with both terms. - The eye is itself a CAZ ensemble. Saccade generation is motor activity in the SMN's sense — the modulator predicts its sensory consequences from the eye's own efference, the same way it predicts the head's.
It does not say:
- That the current predictor + flat 8 × 8 modulator handle combined head + eye motion cleanly. They do not — the ×1.3 +body-yaw contrast is well below the ×3 threshold for a confident PASS. The bottleneck is the predictor's approximations + the modulator's single-floor calibration across patches with very different local content, not the architecture itself.
- Anything about depth, parallax, or saccade dynamics. The static-world assumption holds (the camera rotates about its own optical center); the saccades are simple-PD, not biologically realistic; the eye has only one DOF (no pitch); the modulator has one floor per patch, not per region. These are the next experiments.
What it adds to the assumptions
Common assumptions hold, plus the P0-visual ones. This experiment adds these specifics:
- The eye has its own CAZ pair (an opponent actuator pair on its yaw hinge), driven by a basic random-fixation saccade generator.
- The forward model predicts the next frame from the sum of head and eye
yaw displacements between rendered frames, using a per-column
sec²(α)correction so the warp tracks rotation faithfully across the whole image (not just the centre). - The camera renders at 100 Hz (
RENDER_EVERY = 2); the per-frame Δθ under combined head + eye motion is small enough that the predictor's approximations stay in their accurate regime, except at FOV edges where the rendering sampling itself becomes a noise source.
What is not added: depth, parallax, eye pitch, motion blur, multiple zonal CAZs on the eye, asymmetries between left and right eyes. The next experiment in the visual series will raise CAZ density on the eye itself — the natural setting in which the +body-yaw difficulty becomes a separately tunable problem rather than a global ceiling.
Why this experiment is in the bench
It is the bench's first concrete claim that the SMN's architecture is CAZ- indexed, not body-indexed. The reafference register anchors at any CAZ pair whose motion the agent can predict from its own efference — body, head, eye, or any combination. The −body-yaw run is the cleanest statement of that claim the bench has produced so far. The +body-yaw run is the cleanest statement of where the predictor + flat modulator stop being enough — and therefore the cleanest motivation for the next experiment.
Run it
cd experiments && ../.venv/bin/python p1_visual.py
Outputs: figures/p1_visual.png. Runtime: ~45 s on a laptop CPU.